[1]:
from copy import deepcopy
from dataclasses import dataclass
from typing import Optional, List, Tuple
import numpy as np
import numpy.random as rnd
import matplotlib.pyplot as plt
from alns import ALNS
from alns.accept import SimulatedAnnealing
from alns.select import AlphaUCB
from alns.stop import MaxIterations, MaxRuntime
[2]:
%matplotlib inline
[3]:
SEED = 2345
The permutation flow shop problem
This notebook implements ideas of Stützle and Ruiz (2018).
In the permutation flow shop problem (PFSP), a set of jobs \(N=\{1, \dots, n\}\) has to be processed on a set of machines \(M = \{1, \dots, m\}\). Every job \(j\) requires a processing time \(p_{ij}\) on machine \(i\). Moreover, all \(n\) jobs have to be processed in the same order on every machine, and, the jobs follow the same machine order, starting from machine \(1\) and ending at machine \(m\). The objective is to find a permutation of the jobs, describing the order in which they are processed, such that the maximum completion time is minimized. This is also known as minimizing the makespan.
In this notebook, we demonstrate how to use ALNS to solve PFSP, which is known to be NP-hard. We will also cover some advanced features of the alns package, including autofitting the acceptance criterion, adding local search to a repair operator, and using the **kwargs argument in ALNS.iterate to test different destroy rates.
Data
The Taillard instances are the most used benchmark instances for the permutation flow shop problem. We will use the tai_50_20_8 instance, which consists of 50 jobs and 20 machines.
We use the dataclass decorator to simplify our class representation a little.
[4]:
@dataclass
class Data:
n_jobs: int
n_machines: int
bkv: int # best known value
processing_times: np.ndarray
@classmethod
def from_file(cls, path):
with open(path, "r") as fi:
lines = fi.readlines()
n_jobs, n_machines, _, bkv, _ = [
int(num) for num in lines[1].split()
]
processing_times = np.genfromtxt(lines[3:], dtype=int)
return cls(n_jobs, n_machines, bkv, processing_times)
DATA = Data.from_file("data/tai50_20_8.txt")
Let’s plot a Gantt chart of a random schedule.
[5]:
def compute_completion_times(schedule):
"""
Compute the completion time for each job of the passed-in schedule.
"""
completion = np.zeros(DATA.processing_times.shape, dtype=int)
for idx, job in enumerate(schedule):
for machine in range(DATA.n_machines):
prev_job = completion[machine, schedule[idx - 1]] if idx > 0 else 0
prev_machine = completion[machine - 1, job] if machine > 0 else 0
processing = DATA.processing_times[machine, job]
completion[machine, job] = max(prev_job, prev_machine) + processing
return completion
def compute_makespan(schedule):
"""
Returns the makespan, i.e., the maximum completion time.
"""
return compute_completion_times(schedule)[-1, schedule[-1]]
[6]:
def plot(schedule, name):
"""
Plots a Gantt chart of the schedule for the permutation flow shop problem.
"""
n_machines, n_jobs = DATA.processing_times.shape
completion = compute_completion_times(schedule)
start = completion - DATA.processing_times
# Plot each job using its start and completion time
cmap = plt.colormaps["rainbow"].resampled(n_jobs)
machines, length, start_job, job_colors = zip(
*[
(i, DATA.processing_times[i, j], start[i, j], cmap(j - 1))
for i in range(n_machines)
for j in range(n_jobs)
]
)
_, ax = plt.subplots(1, figsize=(12, 6))
ax.barh(machines, length, left=start_job, color=job_colors)
ax.set_title(f"{name}\n Makespan: {compute_makespan(schedule)}")
ax.set_ylabel(f"Machine")
ax.set_xlabel(f"Completion time")
ax.set_yticks(range(DATA.n_machines))
ax.set_yticklabels(range(1, DATA.n_machines + 1))
ax.invert_yaxis()
plt.show()
[7]:
plot(
rnd.choice(range(DATA.n_jobs), size=DATA.n_jobs, replace=False),
"A random schedule",
)
Solution state
[8]:
class Solution:
def __init__(
self, schedule: List[int], unassigned: Optional[List[int]] = None
):
self.schedule = schedule
self.unassigned = unassigned if unassigned is not None else []
def objective(self):
return compute_makespan(self.schedule)
def insert(self, job: int, idx: int):
self.schedule.insert(idx, job)
def opt_insert(self, job: int):
"""
Optimally insert the job in the current schedule.
"""
idcs_costs = all_insert_cost(self.schedule, job)
idx, _ = min(idcs_costs, key=lambda idx_cost: idx_cost[1])
self.insert(job, idx)
def remove(self, job: int):
self.schedule.remove(job)
A key component in ruin-and-recreate algorithms is a fast way to compute the best insertion place for an unassigned job. In the PFSP, a naive approach is to try all \(O(n)\) insertion positions and compute for each the resulting makespan in \(O(nm)\) time. This has total time complexity \(O(n^2m)\). A more efficient way is to use Taillard’s
acceleration, which is a labeling algorithm that reduces this entire procedure to only \(O(nm)\) time. We use this to implement all_insert_cost.
[9]:
def all_insert_cost(schedule: List[int], job: int) -> List[Tuple[int, float]]:
"""
Computes all partial makespans when inserting a job in the schedule.
O(nm) using Taillard's acceleration. Returns a list of tuples of the
insertion index and the resulting makespan.
[1] Taillard, E. (1990). Some efficient heuristic methods for the
flow shop sequencing problem. European Journal of Operational Research,
47(1), 65-74.
"""
k = len(schedule) + 1
m = DATA.processing_times.shape[0]
p = DATA.processing_times
# Earliest completion of schedule[j] on machine i before insertion
e = np.zeros((m + 1, k))
for j in range(k - 1):
for i in range(m):
e[i, j] = max(e[i, j - 1], e[i - 1, j]) + p[i, schedule[j]]
# Duration between starting time and final makespan
q = np.zeros((m + 1, k))
for j in range(k - 2, -1, -1):
for i in range(m - 1, -1, -1):
q[i, j] = max(q[i + 1, j], q[i, j + 1]) + p[i, schedule[j]]
# Earliest relative completion time
f = np.zeros((m + 1, k))
for l in range(k):
for i in range(m):
f[i, l] = max(f[i - 1, l], e[i, l - 1]) + p[i, job]
# Partial makespan; drop the last (dummy) row of q
M = np.max(f + q, axis=0)
return [(idx, M[idx]) for idx in np.argsort(M)]
Destroy operators
We implement two destroy operators: a random job removal operator, and an adjacent job removal operator. Both destroy operators rely on the n_remove parameter. We set a default value of 2 in case it’s not provided. We will show later how we can experiment with different values for n_remove.
[10]:
def random_removal(state: Solution, rng, n_remove=2) -> Solution:
"""
Randomly remove a number jobs from the solution.
"""
destroyed = deepcopy(state)
for job in rng.choice(DATA.n_jobs, n_remove, replace=False):
destroyed.unassigned.append(job)
destroyed.schedule.remove(job)
return destroyed
[11]:
def adjacent_removal(state: Solution, rng, n_remove=2) -> Solution:
"""
Randomly remove a number adjacent jobs from the solution.
"""
destroyed = deepcopy(state)
start = rng.integers(DATA.n_jobs - n_remove)
jobs_to_remove = [state.schedule[start + idx] for idx in range(n_remove)]
for job in jobs_to_remove:
destroyed.unassigned.append(job)
destroyed.schedule.remove(job)
return destroyed
Repair operator
We implement a greedy repair operator and use a specific ordering for the unassigned jobs: the jobs with the highest total processing times are inserted first. This is also known as the NEH ordering, after Nawaz, Enscore and Ham (1983).
[12]:
def greedy_repair(state: Solution, rng, **kwargs) -> Solution:
"""
Greedily insert the unassigned jobs back into the schedule. The jobs are
inserted in non-decreasing order of total processing times.
"""
state.unassigned.sort(key=lambda j: sum(DATA.processing_times[:, j]))
while len(state.unassigned) != 0:
job = state.unassigned.pop() # largest total processing time first
state.opt_insert(job)
return state
Initial solution
[13]:
def NEH(processing_times: np.ndarray) -> Solution:
"""
Schedules jobs in decreasing order of the total processing times.
[1] Nawaz, M., Enscore Jr, E. E., & Ham, I. (1983). A heuristic algorithm
for the m-machine, n-job flow-shop sequencing problem. Omega, 11(1), 91-95.
"""
largest_first = np.argsort(processing_times.sum(axis=0)).tolist()[::-1]
solution = Solution([largest_first.pop(0)], [])
for job in largest_first:
solution.opt_insert(job)
return solution
[14]:
init = NEH(DATA.processing_times)
objective = init.objective()
pct_diff = 100 * (objective - DATA.bkv) / DATA.bkv
print(f"Initial solution objective is {objective}.")
print(f"This is {pct_diff:.1f}% worse than the best known value {DATA.bkv}.")
Initial solution objective is 3958.
This is 6.7% worse than the best known value 3709.
[15]:
plot(init.schedule, "NEH")
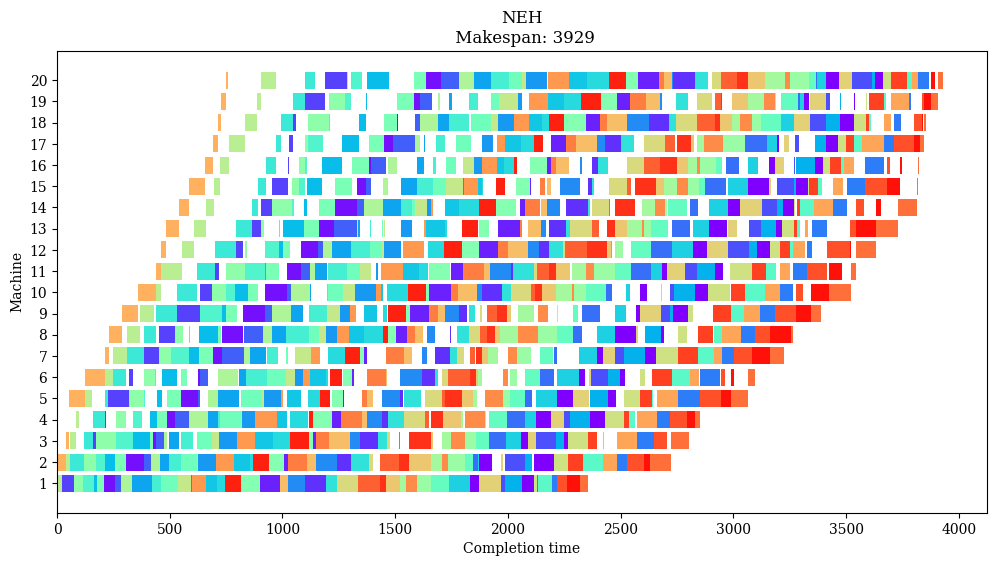
Heuristic solutions
[16]:
alns = ALNS(rnd.default_rng(SEED))
alns.add_destroy_operator(random_removal)
alns.add_destroy_operator(adjacent_removal)
alns.add_repair_operator(greedy_repair)
[17]:
ITERS = 8000
init = NEH(DATA.processing_times)
select = AlphaUCB(
scores=[5, 2, 1, 0.5],
alpha=0.05,
num_destroy=len(alns.destroy_operators),
num_repair=len(alns.repair_operators),
)
stop = MaxIterations(ITERS)
Autofitting acceptance criteria
To use the simulated annealing criterion, we need to determine three parameters: 1) the start temperature, 2) the final temperature and 3) the updating step. These parameters are often calculated using the following procedure:
Start temperature is set to a specific value, such that a first candidate solution is accepted with 50% probability if it is 5% worse than the initial solution.
Final temperature is set to 1.
The updating step is set to the linear/exponential growth rate that is needed to decrease from the start temperature to the final temperature in the specified number of iterations.
Because this is such a common procedure, the SimulatedAnnealing class exposes the autofit method that can determine these parameters automatically. See the documentation for more information.
[18]:
accept = SimulatedAnnealing.autofit(init.objective(), 0.05, 0.50, ITERS)
[19]:
result = alns.iterate(init, select, accept, stop)
[20]:
_, ax = plt.subplots(figsize=(12, 6))
result.plot_objectives(ax=ax)
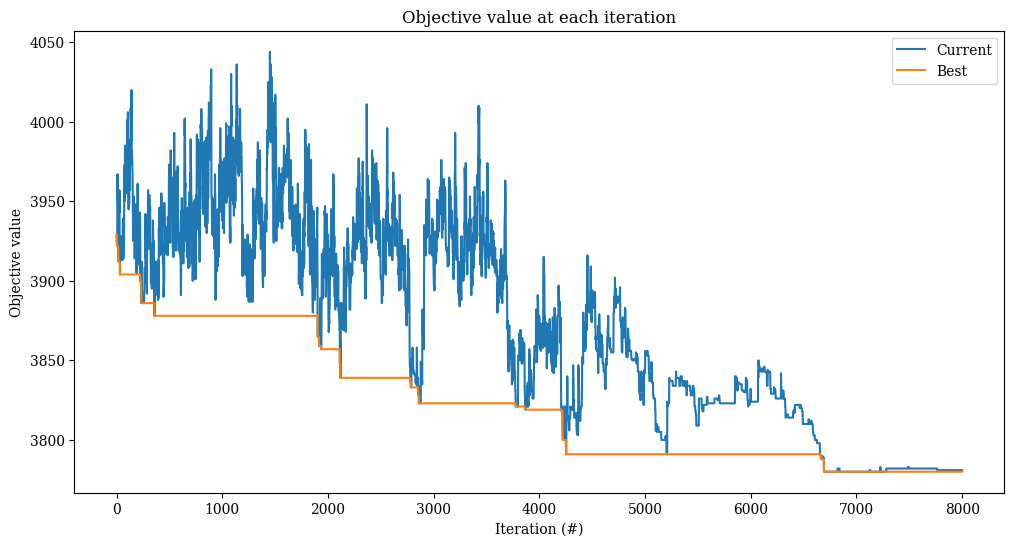
[21]:
solution = result.best_state
objective = solution.objective()
pct_diff = 100 * (objective - DATA.bkv) / DATA.bkv
print(f"Best heuristic objective is {objective}.")
print(f"This is {pct_diff:.1f}% worse than the best known value {DATA.bkv}.")
Best heuristic objective is 3772.
This is 1.7% worse than the best known value 3709.
[22]:
name = "ALNS with random & adjacent removal + greedy repair"
plot(result.best_state.schedule, name)
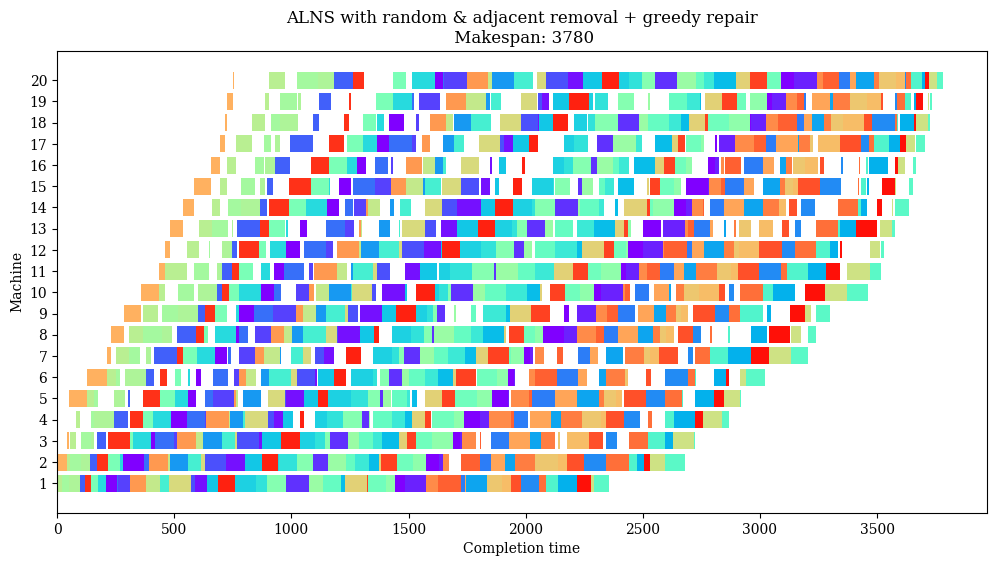
Adding local search to greedy repair
Some ALNS heuristics include a local search after the repair step. This is also the case for the Iterated Greedy algorithm by Ruiz and Stützle (2007), which is a crossover between large neighborhood search and iterated local search. Iterated Greedy is one of the best performing metaheuristics for the PFSP.
There are various ways to implement this. As explained in the documentation, one could implement a perturbation and local search operator and pass this to ALNS as destroy and repair operator, respectively. We do it differently: we make a new repair operator function that adds a local search step after the repair step is completed.
[23]:
def greedy_repair_then_local_search(state: Solution, rng, **kwargs):
"""
Greedily insert the unassigned jobs back into the schedule (using NEH
ordering). Apply local search afterwards.
"""
state = greedy_repair(state, rng, **kwargs)
local_search(state, **kwargs)
return state
def local_search(solution: Solution, **kwargs):
"""
Improves the current solution in-place using the insertion neighborhood.
A random job is selected and put in the best new position. This continues
until relocating any of the jobs does not lead to an improving move.
"""
improved = True
while improved:
improved = False
current = solution.objective()
for job in rnd.choice(
solution.schedule, len(solution.schedule), replace=False
):
solution.remove(job)
solution.opt_insert(job)
if solution.objective() < current:
improved = True
current = solution.objective()
break
[24]:
alns = ALNS(rnd.default_rng(SEED))
alns.add_destroy_operator(random_removal)
alns.add_destroy_operator(adjacent_removal)
alns.add_repair_operator(greedy_repair_then_local_search)
[25]:
ITERS = 600 # fewer iterations because local search is expensive
init = NEH(DATA.processing_times)
select = AlphaUCB(
scores=[5, 2, 1, 0.5],
alpha=0.05,
num_destroy=len(alns.destroy_operators),
num_repair=len(alns.repair_operators),
)
accept = SimulatedAnnealing.autofit(init.objective(), 0.05, 0.50, ITERS)
stop = MaxIterations(ITERS)
result = alns.iterate(init, select, accept, stop)
[26]:
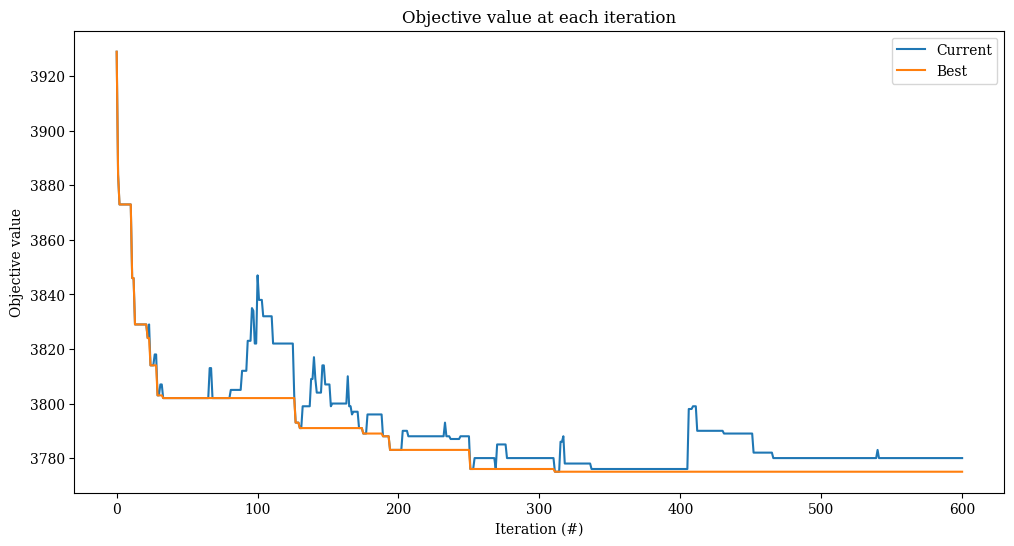
_, ax = plt.subplots(figsize=(12, 6))
result.plot_objectives(ax=ax)
[27]:
solution = result.best_state
objective = solution.objective()
pct_diff = 100 * (objective - DATA.bkv) / DATA.bkv
print(f"Best heuristic objective is {objective}.")
print(f"This is {pct_diff:.1f}% worse than the best known value {DATA.bkv}.")
Best heuristic objective is 3774.
This is 1.8% worse than the best known value 3709.
[28]:
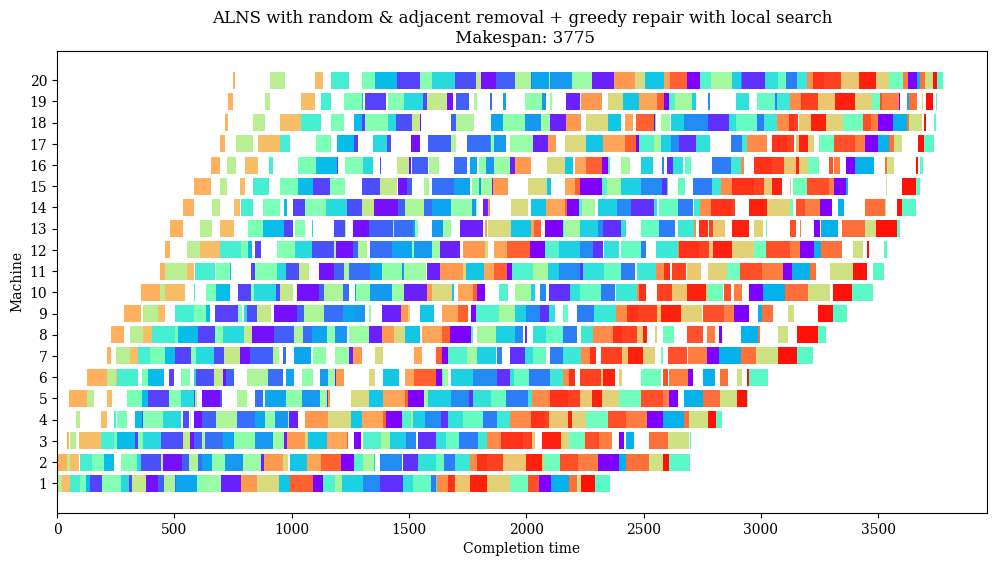
name = "ALNS with random & adjacent removal + greedy repair with local search"
plot(result.best_state.schedule, name)
Tuning the destroy rate
Besides the selection scheme and criteria, ALNS.iterate can also take keyword-arguments. This can be helpful, for instance, when we want to tune parameters of the destroy/repair operators. In our case, we want to test for which values of n_destroy we obtain the best results.
[29]:
alns = ALNS(rnd.default_rng(SEED))
alns.add_destroy_operator(random_removal)
alns.add_destroy_operator(adjacent_removal)
alns.add_repair_operator(greedy_repair)
[30]:
objectives = {}
for n_remove in range(2, 10):
select = AlphaUCB(
scores=[5, 2, 1, 0.5],
alpha=0.05,
num_destroy=len(alns.destroy_operators),
num_repair=len(alns.repair_operators),
)
iters = 2000 / (n_remove * 2) # higher destroy rates use less iterations
accept = SimulatedAnnealing.autofit(init.objective(), 0.05, 0.50, iters)
stop = MaxRuntime(30)
result = alns.iterate(init, select, accept, stop, n_remove=n_remove)
objectives[n_remove] = result.best_state.objective()
[31]:
fig, ax = plt.subplots(figsize=[8, 6])
ax.plot(*zip(*sorted(objectives.items())))
ax.set_title("Final objective value for various n_destroy values")
ax.set_ylabel("Objective value")
ax.set_xlabel("n_destroy");
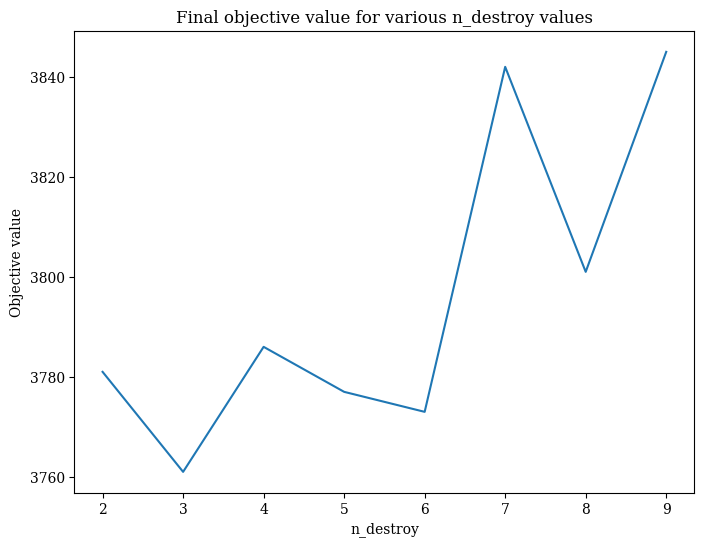
From this simple experiment, it looks like removing 3 works best. Our experiment is clearly too simple to draw serious conclusions from, but this example can be easily extended to include more instances and also more random seeds.
Conclusions
In this notebook, we implemented several variants of adaptive large neighborhood search heuristic to solve the permutation flow shop problem. We obtained a solution that is only 1-2% worse than the best known solution. Furthermore, we showed several advanced features in ALNS, including:
Autofitting acceptance criteria
Adding local search to repair operators
Using the
**kwargsargument inALNS.iterateto tune then_removeparameter in destroy operators